
장애 모니터링 만들기
Updated:
안녕하세요. 오늘은 장애모니터링을 만드는 법에 대해서 간략하게 설명해 드리고자 합니다. 이전에 사용화된 모니터링툴들을 보고 있자면 이걸로 장애인지하는데 문제는 없겠지만 장애 포인트가 어디인지를 명확하게 찾아내는데 이슈가 있어 보였습니다. 자빅스, 스카우트등 무료툴들이 있었지만 많이 부족해 보였고 잘 보지도 않을뿐더러 이전과의 장애인지 상황이 달라지지 않았죠. 그래서 저희는 장애모니터링을 직접 만들어 보고자 하였습니다.
왜
장애가 발생했는데 아무도 인지를 못하고 있다가 사업부/기획을 통해 인지 하는 경우가 많다. 1년간의 통계를 내어 보고 대응지연시간을 측정해 보았더니 평균 20시간정도 소요가 된게 있었습니다. 물론 시스템 장애로 인해서 평균시간이 길어 졌지만 짧은건 수분내로 처리를 했을듯 한데 길게는 하루를 넘긴적도 있긴 하네요.
장애인지가 늦어졌을까?
직원들이 운영/프로젝트 업무를 하다 보니 장애대응팀이 별도로 있는건 아니었습니다. 운영업무를 하면서 장애대응도 수시로 하였죠. 물론 장애라는게 출퇴근시간에 맞춰서 일어난적이 없기 때문에 장애 발생서 보고체계 및 대응 메뉴얼도 부족했던건 사실이었습니다.
보고를 왜 안하는거지?
장애가 발생하고 있지만 이게 보고대상인지 아닌지를 명확하게 판단하지 못한 직원들이 두루 있었고 누락되어서 장애가 보고 되지 않은체 넘어간적도 있었죠. 뒤늦게 협업회의시간에 이야기가 되서 난감한적이 종종 있었지요.
대응 안하니?
장애가 발생해서 대응까지 담당자가 누구인지 어떻게 전달을 해야 하는건지 직원들은 난감해 했습니다. 일단 일일이 물어 보고 다니거나 본인이 스스로 해결하려고 하려다가 늦어지거나 초기대응시간을 넘긴적이 많았죠 .
위에 글을 읽어 보시면 나름 우리회사도 이런적이 있다. 라고 생각하신분들이 계실겁니다. 물론 최근 장애에 대한 인지가 높아졌고 별도의 장애대응팀도 있다고 하니 이러한 장애를 빠르게 해결하는 방법도 자체적으로 구축을 하지 않았을까 합니다.
시작
먼저 장애대응을 하려면 장애인지를 빠르게 할수 있는 무언가가 있어야 한다고 생각했습니다.
기존에 쓰고 있던 솔루션 “스카우터” “자빅스” 이걸로 장애인지가 안될까?
스카우트/자빅스 화면에서 장애를 과연 빠르게 인지 할까? 의문점이 생겼습니다. 물론 계속 들여다 보면 이슈감지는 하게 되겠고 어느 순간데 데이터베이스 CPU가 상승 되거나 네트워크 트레픽 등등 알수는 있을겁니다. 그건 개발자 입장에서는 거의 희박하다고 생각이 됩니다. 첫번째 저희가 생각한 장애 인지는 UI를 개선하여 빠르게 장애를 볼수 있는 화면이 필요했습니다. 두번째. 장애가 어느곳에서 일어 나고 있는지에 대한 히스토리를 파악할수 있냐 인데 위에 어플리케이션으로 장애를 인지 하더라도 서버를 들어가서 로그를 보기 전까지는 어디에서 장애가 발생했는지 알수가 없죠.
일단 두가지 목표를 가지고 진행하기로 하였습니다.
어떻게 만들까?
이제 장애프로그램을 만들기 위한 아키텍처가 필요해 보입니다.
그라파나 / ELK Stack 두가지 솔루션을 가지고 고민을 했습니다.
 위에서도 말했듯이 인지가 가장 큰 목적이라서 저희는 그라파나를 통한 UI를 좀더 다양하게 만들어 보기로 했습니다.
위에서도 말했듯이 인지가 가장 큰 목적이라서 저희는 그라파나를 통한 UI를 좀더 다양하게 만들어 보기로 했습니다.
만들면 뭐가 좋아지는건지…
- 문제 발생시 빠른 장애 감지로 신속한 장애대응이 가능
- 사용 빈도가 낮은 자원에 대한 지원을 종료
- 보다 빠른 검색을 통한 장애요소 파악
이제 만들어 볼까?
Grafana
설치를 하기위해서는 먼저 자원과 사용자를 이해해야 했고 어떻게 대시보드를 만들어서 배포 할지도 고민해야 했다. 그래서 어떠한 어플리케이션에서 어떠한 자료를 어떻게 받는지를 조사 하고 거기에 맞게 기본 대시보드를 구성하기로 했다. 먼저는 어플리케이션에서 로그를 수집하고 장애가 발생시에 어떻게 보여줄지만 먼저 고민하였다. !!! 설치 가이드의 경우 인터넷에 많이 나와 있기에 따로 언급은 하지 않게습니다.
Loki
모든 데이터는 로키시스템에 저장된다고 보면 된다 단 로키의 경우 저장공간이 한정적이라 S3에 최근 3개월로그를 저장하고 보기로 하였다. 3개월로 지정한 이유는 그 이상의 데이터를 가지고 왔을때엔 로키에서 볼수 있는 속도가 너무 느리기 때문이다.
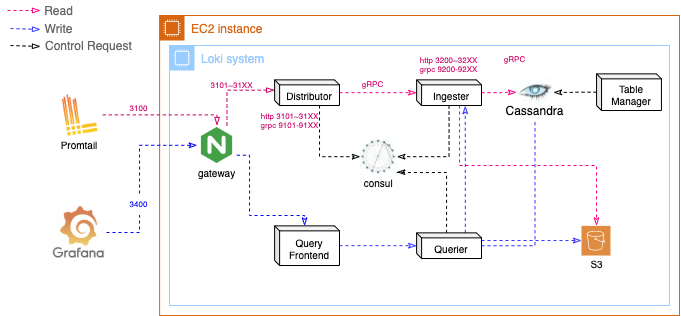
읽기 과정
- Query-Frontend 가 데이터에 대한 http 요청을 수신후 설정에 따라 요청을 분할하여 Querier에게 전달(특정 시간간격으로 쿼리분할)
- Querier가 요청을 모든 Ingester 에 전달하여 데이터 검색(Ingester의 인메모리 데이터)
- Ingester에 데이터가 있다면(짧은 시간내의 검색) 해당 데이터를 반환
- Ingester들로 부터 데이터를 전달받지 못한 Querier는 Chunk Store(S3)에서 데이터를 받아 데이터를 찾음
- Querier는 모든 데이터의 중복을 제거하고, Query-Frontend에 전달
- Query-Frontend는 분할된 요청에 대한 데이터를 Querier로 부터 받아 알맞게 정렬후 최종 결과 전달
쓰기 과정
- Table-manager는 설정에 정해진기간단위로 Index table을 Cassandra에 생성
- Distributor가 Promtail로 부터 데이터스트림을 수신
- 각 스트림은 hashing 되어 replication factor 만큼 복제되어 ingester들에게 gRPC를 통해 전달 (Consul이 해당 gRPC port를관리)
- 각 Ingester들은 log를 압축하여 Chunk로 생성하고 해당 Chunk들의 상태를 index table 에 업데이트
- Chunk 가 제한용량에 도달하거나, Chunk 생성후 특정기간이 지났을때 설정에 저장된 기간이 지난후 Chunk Store(S3)에 업로드
- Table-manager는 설정된 기간이 지난후의 index table을 삭제
- 업로드된 Chunk는 S3정책으로 91일 이상 삭제하도록 제한
모듈구성
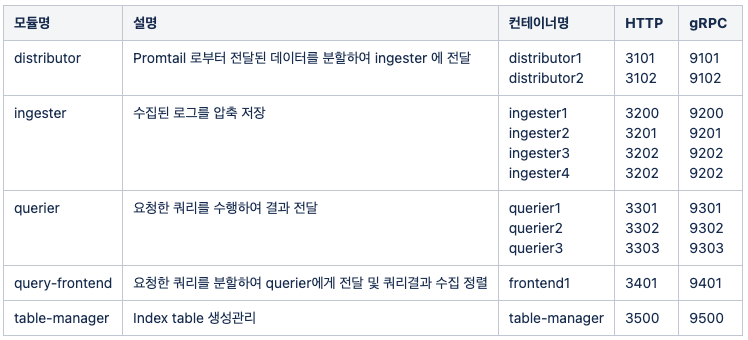
기타구성

Promtail
프롬테일의 경우 각 서버에 설치 하여 어플리케이션 로그를 로키로 보내주는 역활을 한다.
1 mkdir /app/promtail
2 mkdir /app/promtail/config
3 cd /app/promtail/config
4 wget https://raw.githubusercontent.com/grafana/loki/v2.2.0/cmd/promtail/promtail-docker-config.yaml -O promtail-config.yaml # promtail 설정파일 복사
5 vim promtail-config.yaml
a positions > filename 값을 /app/promtail/config/positions.yaml 로 변경 # log 파일을 어디까지 읽었는지에 대한 정보를 저장
b clients > url 값의 도메인을 Loki와 맞춰줌 # 해당 promtail서버와 loki서버의 port는 오픈되어있어야함
c scrape_configs > static_configs > __path__ 를 log파일이 있는 위치로 지정 # 아래 이미지는 nginx 기준
6 docker run --name promtail -d --user $(id -u) -v /app:/app grafana/promtail:2.2.0 -config.file=/app/promtail/config/promtail-config.yaml # promtail container 실행
→ docker run #docker image로부터 container 생성
→ --name promtail # docker container의 이름을 promtail로 생성
→ -d # docker container를 background로 실행
→ --user $(id -u) # docker container를 해당 user로 실행 (각서버의 메인 유저로 실행)
→ -v /app:/app # docker container안의 /app 경로를 실제 서버의 /app경로로 mount
→ grafana/promtail:2.2.0 # container로 실행항 promtail 이미지
→ -config.file=/app/promtail/config/promtail-config.yaml # promtail이 필요로하는 설정파일의 위치 지정 (앞에서 마운트해주지 않으면 container안에서 해당 경로의 파일을 찾지 못하여 실행이 안됨)
Yaml 설정을 변경하여 로키까지의 데이터 축적이 되는지 확인해 봐야 할 필요가 있다.
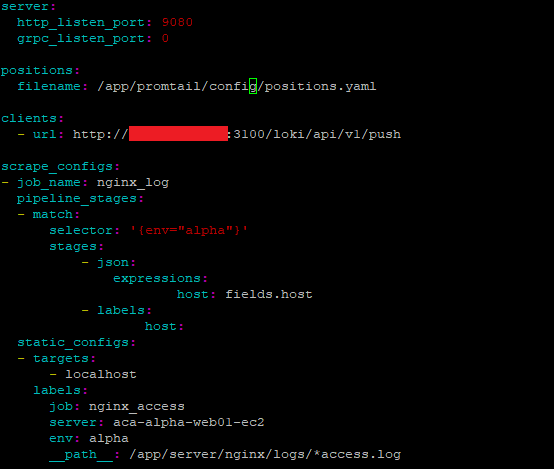
사용자에게 맞는 …
먼저 개발자들에게 필요한 대시보드가 필요했다. 앞에서 언급했듯이 빠른 장애 인지가 필요하였고 에러를 빨리 보고 처리할수 있게 큰 UI를 만들고자 했다.
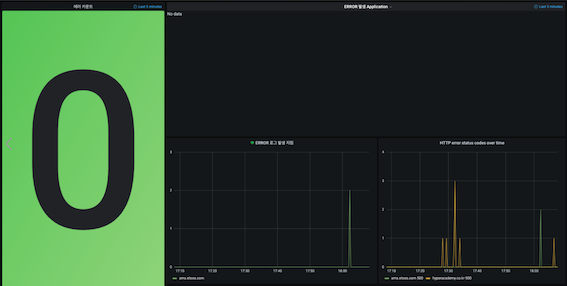
가장 큰 숫자는 애러가 한개라도 있다면 숫자가 바뀌면서 빨강색 바탕화면으로 변하게 된다. 그러면 그 색상만으로도 에러가 있다는걸 감지 할수 있다. 이렇게 해서 장애 인지는 끝났다. 그런데 장애 인지하고 오느곳에 문제가 있는지 찾아야 했다. 그래서 그라파타의 검색을 이용하기로 했다.
한가지 이슈가 발생하였다. 콘솔로그가 너무 방대한 양으로 쌓이고 있다는 것이다. 대부분 Query 라서 일단 콘솔과 쿼리를 분리하기로 했고 쿼리를 찾기 위해 Hash code 를 부여하기로 하였다.
2021-05-25 18:32:35.710 -INFO 10788 --- [http-nio-8081-exec-595] k.c.e.p.d.PayService : Service start
2021-05-25 18:32:35.710 -DEBUG 10788 --- [http-nio-8081-exec-595] oggingSupportStatementHandlerInterceptor : boundSql : select distinct
t1.uf_seq
,t1.urfee_cd
,t1.uee_name
,t1.tion_yn
,t1.dount_yn
,t1.cge_type
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 중략 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
,t1a.crge_type
) t1
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 중략 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
group by t1.uf_seq
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 중략 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
,t1.y_seq
,t1.uy_seq
order by t1.ue_cd
2021-05-25 18:32:35.710 -INFO 10788 --- [http-nio-8081-exec-595] k.c.e.p.d.XXXService
이렇게 로그가 기록되어 있다면 console.log 와 query.log 로 분리하여 찾을때 불편함이 있겠지만 로그양을 좀 줄이기로 했다.
### console.log
2021-05-25 18:32:35.710 -INFO 10788 --- [http-nio-8081-exec-595] k.c.e.p.d.XXXService : Service start
2021-05-25 18:32:35.710 -DEBUG 10788 --- [http-nio-8081-exec-595] p6spy : "QHash":"8c6b7778672a4222bf18d91a035cd86e"
2021-05-25 18:32:35.710 -INFO 10788 --- [http-nio-8081-exec-595] k.c.e.p.d.XXXService : Service end
### query.log
{"QHash":"8c6b7778672a4222bf18d91a035cd86e", "sql":"select distinct t1.uf_seq, t1.use ~~~ 중략 ~~~"}
그라파나에서 검색시 아래 화면에 다음과 같이 기록을 해주면 검색이 된다.
{env="prod",query!="true", job="XXX", host="도메인", server="서버명" } //일반적인 로그 검색시
{env="prod",query!="true", job="XXX", host="도메인", server="서버명" } |= "hash coder값" // 쿼리로그 검색시
이렇게 만들고 보니 서버로그를 보기 위해 콘솔화면으로 접근할 필요도 없고 장애인지와 장애포인트를 명확하게 알수가 있어서 소요시간을 단축하는 효과가 생겼다. 같이 만들어 준 팀원들에게 감사드리며 이상 글을 마치고자 합니다.
Comments